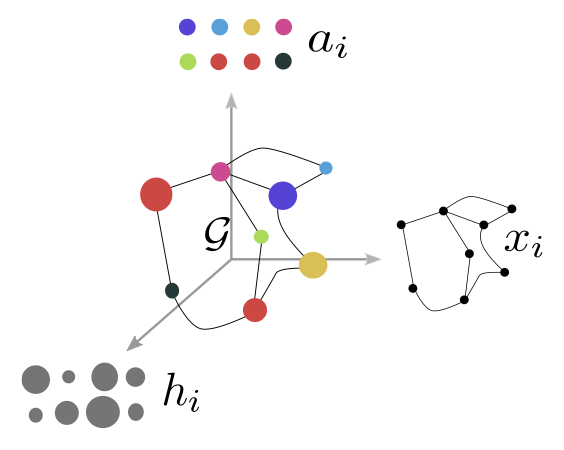
Gromov-Wasserstein is an Optimal Transport metric designed to align heterogeneous distributions. We have shown it could be used to compare graphs and proposed a sliced version to overcome its computational burden.
Romain Tavenard
Professor
Université de Rennes 2 / IRISA-Obelix
Gromov-Wasserstein is an Optimal Transport metric designed to align heterogeneous distributions. We have shown it could be used to compare graphs and proposed a sliced version to overcome its computational burden.

This section gathers Machine Learning tools dedicated to time series with no specific focus on environmental data.

A lot of earth observation data are timestamped. Designing ML techniques that can handle this time dimension can often lead to much improved performance. We have so far turned our focus on 3 different types of environmental data: chemistry data in streams, remote sensing data (such as satellite image time series) and ship trajectory data.

We have been using time-sensitive topic models (such as Probabilistic Latent Semantic Motifs or Hierarchical Dirichlet Latent Semantic Motifs) to perform action recognition in videos. More recently, we have turned our focus towards the design of richer models to better model continuous processes in continuous time.

Our main goal in this project was to introduce new indexing schemes that were able to efficiently deal with time series. One contribution in this field was iSAX+, an approximate-lower-bound-based indexing scheme for DTW. Some works about vector data indexing are also cited here.
The growing use of lots of low-level sensors instead of few higher-level ones implies the use of dedicated pattern extraction methods. To do so, we have worked on the already existing T-patterns algorithm so that it can efficiently scale up to larger volumes of data.